Makine Öğrenmesi | Clustering (Kümeleme) Teknikleri

Kümeleme (Clustering) , makine öğrenmesi konseptlerinden biri olan Denetimsiz Öğrenme (Unsupervised Learning) için önemli bir kavramdır. Kümeleme algoritmaları basitçe veri kümesindeki elemanları kendi arasında gruplamaya çalışır. Burada kaç grup olacağı bizim inisiyatifimizde olan bir bilgi de olabilir veyahut en uygun küme sayısını algoritmanın kendisi de belirleyebilir. Kümeleme kavramının derinlerine inmeden önce denetimsiz öğrenme konseptinden biraz bahsetmekte fayda var. Hadi başlayalım :)
Denetimsiz Öğrenme (Unsupervised Learning)
Denetimsiz öğrenme , oluşturulan modelde kullanıcının herhangi bir denetiminin olmadığı makine öğrenmesi tekniğidir. Modelin yeni gelen verilere nasıl davranacağı kullanılan algoritmaya bağlıdır. Örneğin kümeleme yönteminde verilerin kendi aralarında bir gruplamaya tabi tutulduğunu söyledik. Fakat oluşan bu gruplardaki verilerin hangi veri grubuna ait olduğunu bilmiyoruz , daha doğrusu bunlar aslında etiketsiz (unlabelled) verilerdir. Dolayısıyla algoritma yeni gelen bir veriyi gruplamak için böyle bir bilgiye sahip değil , sahip olsaydı eğer bu yazımız Kümeleme yerine ‘Sınıflandırma ’ tekniğine ait bir yazı olurdu. Ayrıca denetimsiz öğrenme algoritmaları denetimli öğrenmeye nazaran daha karmaşık süreçler içerebildiğinden dolayı diğer öğrenme yöntemlerine kıyasla daha öngörülemez de (sağı solu belli olmaz kısaca :)) olabilir.
Gelelim şimdi kümelemeye…
Kümeleme tekniğinde kullanılabilecek birkaç farklı yaklaşım var. Bu yazımızda biz K-means kümeleme algoritmasını ve Hierarchical clustering algoritmalarını incelemeye çalışalım.
K-Means Kümeleme Algoritması
Adım adım çalışma mantığına bakalım. İlk adımda kümeler için bir merkez noktası rastgele olarak belirlenir.

Merkez eleman dışındaki elemanlar en yakın merkez noktasına göre kümelenir. Bunun için her bir elemanın merkez noktalara olan uzaklıkları ölçülür.

Kümelenen elemanlarımız böyle bir hal alır.

Ardından aynı kümeler içerisinde tekrar bir merkez noktası hesaplaması yapılır.

Ardından merkez noktası stabil hale gelinceye dek ilk iki adım tekrarlanır.

Ve son :). K-means algoritması çoğu büyük — küçük veri kümesi için ideal bir algoritma olsa da her algoritmada olduğu gibi onun da bazı problemleri vardır. Örneğin bu örnekte küme sayısını üç olarak ele aldık fakat modelde kaç adet küme olacağı bilgisi kullanıcıdan alındığı için belirtilen bu sayı her zaman optimum değer olmayabilir. Bir diğer problem ise başlangıçta rastgele olarak atanan merkez noktaları her zaman başarılı sayılabilecek bir kümeleme işlemini başlatmayabilir. Çünkü dikkat ettiyseniz algoritma başlangıçta rastgele atanan bu merkez noktalarına göre şekillenmekte. Tabii bunun için farklı çözümler de düşünülmüş. Örneğin başlangıçta atanan bu rastgele noktalar için K-means++ algoritması mevcut. Optimum küme sayısını belirlemek için ise WCSS (within-cluster sums of squares) isminde bir yöntem kullanılmakta ki bu kavram üzerinde durmakta fayda var. Kendisinin şöyle bir formülü var:

Formül kısaca her bir küme için o kümedeki noktaların merkez noktalarına olan uzaklıklarının karelerinin toplamını ifade ediyor. Peki bu değerin küme sayısını belirlemedeki rolü nedir?
Bunun için önce bir kümeleme algoritmasının başarı kriterini konuşmamız gerekir. Şayet bir kümeleme algoritması küme elemanları arasındaki mesafeyi ne kadar minimum ve her bir küme arasındaki mesafeyi de ne kadar maksimum tutabiliyorsa o kadar başarılı bir kümeleme yapmıştır diyebiliriz. Bu kriteri küme sayısını olabildiğince artırarak gerçekleştirebilir miyiz?. Aslında cevap evet. Küme sayısı arttıkça küme içindeki her bir eleman arası mesafe azalmış olacaktır ve WCSS değeri de bununla beraber azalmış olacaktır. O halde neden WCSS değerini 0 yapana kadar küme eklemiyoruz düşüncesi aklımıza gelebilir. Bunun sonucunda da her bir eleman kendi başına birer küme olarak karşımıza çıkacak ve modelimiz overfittinge yani ezberleme durumuna uğrayacaktır. Peki o zaman optimum noktayı nasıl belirleyebiliriz?. Bunun için WCSS grafiğinde dirsek noktası diye tabir edilen bir değere bakmamız yeterlidir. Şöyle ki:

Burada eğimin ani olarak değiştiği noktalardan birini k-point olarak alabiliriz. Örneğin 3 değeri gibi. Bu K-means algoritmasını kullanan modelimiz için optimum küme sayısı olabilir.
Hierarchical Clustering Algoritması
Bu yöntemde ise iki adet yaklaşım bulunmakta:
Agglomerative: Her bir veri öncelikle kendine ait bir küme oluşturur. Ardından birbirine en yakın olan iki küme birleşerek yeni bir küme oluşturur ve bu işlem tek bir büyük küme oluşuncaya dek devam eder.
Divisive: Bu yaklaşımda ise tüm veriler öncelikle tek bir küme içerisinde ele alındıktan sonra her bir veri noktası birer küme oluncaya dek bölünme işlemi gerçekleşiyor.

Peki bu algoritmada da kaç küme belirlersek sonuç en iyi oluru nasıl belirleyebiliriz?. Bunun için kümelerimizin dendrogram grafiğine bakarız. O da nedir?
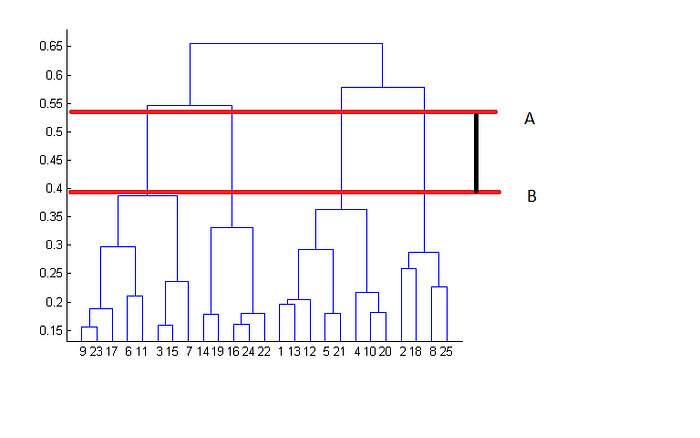
Dendrogram, birleşen kümeleri ve bu kümeler arasındaki mesafeyi belirten bir grafik. Bu grafikte optimum küme sayısı ise bir küme ile kesişmeden yatay olarak çizilebilen iki çizgi arası mesafenin maksimum olduğu noktadaki dikey küme birleşim çizgilerinin sayısıdır. Bu grafikte sayarsak eğer hiyerarşik kümeleme için optimum küme sayısının 4 olduğunu söyleyebiliriz.
K-Means ile Hierarchical Clustering Karşılaştırması
- Hierarchical clustering büyük veri kümeleri için uygun değildir fakat K-means uygundur. Sebebi ise K-means O(n) zaman karmaşıklığına sahip iken hierarchical clustering O(n²) karmaşıklığa sahiptir.
- K-means algoritması her yeniden çalıştırıldığında rastgele bir başlangıç merkez noktası belirleyeceğinden sonuçlar farklılık gösterebilir.
- K-means algoritması verinin kaç kümeye bölüneceği hakkındaki bilgiyi kullanıcıdan beklemektedir ve bu bilgi her zaman optimum değer olmayabilir (WCSS kullanmadığımızı farz edersek). Fakat hierarchical clustering algoritmasında optimum küme sayısı dendrogram grafiği üzerinden yorumlanabilir.
Bu yazımda makine öğrenmesinde kümeleme (clustering) tekniğine ve bu teknik içerisinde kullanılan bazı algoritmalara değinmeye çalıştık. Öneri ve görüşleriniz için bana LinkedIn üzerinden ulaşabilirsiniz. Başka yazılarda görüşmek üzere :).
Faydalandığım Kaynaklar:
